前言
本文主要介绍的是ElasticSearch集群和kinaba的安装教程。
ElasticSearch介绍
ElasticSearch是一个基于Lucene的搜索服务器,其实就是对Lucene进行封装,提供了 REST API 的操作接口.
ElasticSearch作为一个高度可拓展的开源全文搜索和分析引擎,可用于快速地对大数据进行存储,搜索和分析。
ElasticSearch主要特点:分布式、高可用、异步写入、多API、面向文档 。
ElasticSearch核心概念:近实时,集群,节点(保存数据),索引,分片(将索引分片),副本(分片可设置多个副本) 。它可以快速地储存、搜索和分析海量数据。 ElasticSearch使用案例:维基百科、Stack Overflow、Github 等等。
ElasticSearch集群安装
一、环境选择
ElasticSearch集群安装依赖JDK,本文的ElasticSearch版本为6.5.4,对应的Kibana也是6.5.4,这里顺便说下Kibana的版本最好不要低于ElasticSearch的版本,JDK的版本为1.8。
下载地址:
ElasticSearch-6.5.4: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.tar.gz
Kibana-6.5.4: https://artifacts.elastic.co/downloads/kibana/kibana-6.5.4-linux-x86_64.tar.gz
JDK1.8 : http://www.oracle.com/technetwork/java/javase/downloads
ElasticSearch有几个重要的节点属性,主节点、数据节点、查询节点、摄取节点,其中主节点、数据节点最重要的,因此本文就只主要介绍这两个节点的安装,剩下的节点属性在配置文件那块进行说明。
ElasticSearch集群安装表格:
二、Linux配置
在安装ElasticSearch之前,我们需要对Linux的环境做一些调整,防止在后续过程中出现一些问题!
1、修改最大内存限制
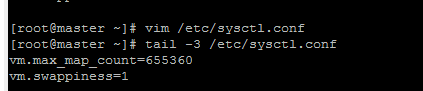
修改sysctl.conf文件
vim /etc/sysctl.conf
在末尾增加如下配置:
vm.max_map_count = 655360
vm.swappiness=1
然后保存退出,输入以下命令使其生效
sysctl -p
保存退出,输入以下命令执行使其生效
sysctl -p
使用命令查看:
tail -3 /etc/sysctl.conf
2、修改最大线程个数
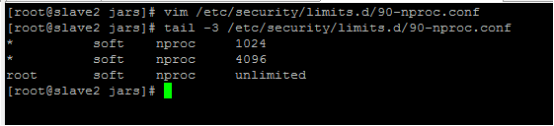
修改90-nproc.conf文件
vim /etc/security/limits.d/90-nproc.conf
注:不同的linux服务器90-nproc.conf可能文件名不一样,建议先在/etc/security/limits.d/查看文件名确认之后再来进行更改。
将下述的内容
soft nproc 2048
修改为
soft nproc 4096
使用命令查看:
tail -3 /etc/security/limits.d/90-nproc.conf
3、修改最大打开文件个数
修改limits.conf
vim /etc/security/limits.conf
在末尾添加如下内容:
hard nofile 65536
soft nofile 65536

4、防火墙关闭
说明:其实可以不关闭防火墙,进行权限设置,但是为了方便访问,于是便关闭了防火墙。每个机器都做!!!
关闭防火墙的命令
CentOS 6
查询防火墙状态:
[root@localhost ~]# service iptables status
停止防火墙:
[root@localhost ~]# service iptables stop
启动防火墙:
[root@localhost ~]# service iptables start
重启防火墙:
[root@localhost ~]# service iptables restart
永久关闭防火墙:
[root@localhost ~]# chkconfig iptables off
永久关闭后启用:
[root@localhost ~]# chkconfig iptables on
CentOS 7
关闭防火墙
systemctl stop firewalld.service
三、JDK安装
1,文件准备
解压下载下来的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移动到opt/java文件夹中,没有就新建,然后将文件夹重命名为jdk1.8
mv jdk1.8.0_144 /opt/java
mv jdk1.8.0_144 jdk1.8

2,环境配置
首先输入 java -version
查看是否安装了JDK,如果安装了,但版本不适合的话,就卸载

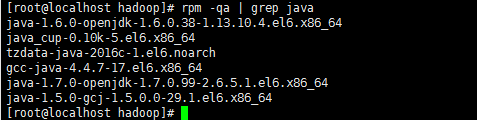
输入
rpm -qa | grep java
查看信息
然后输入:
rpm -e --nodeps “你要卸载JDK的信息”
如: rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64

确认没有了之后,解压下载下来的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移动到opt/java文件夹中,没有就新建,然后将文件夹重命名为jdk1.8。
mv jdk1.8.0_144 /opt/java
mv jdk1.8.0_144 jdk1.8
然后编辑 profile 文件,添加如下配置
输入: vim /etc/profile
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
添加成功之后,输入:
source /etc/profile
使配置生效,然后查看版本信息输入:
java -version

四、ElasticSearch安装
1,文件准备
将下载好的elasticsearch文件解压
输入:
tar -xvf elasticsearch-6.5.4.tar.gz
然后移动到/opt/elk文件夹 里面,没有该文件夹则创建,然后将文件夹重命名为masternode.
在/opt/elk输入:
mv elasticsearch-6.5.4 /opt/elk
mv elasticsearch-6.5.4 masternode
2,配置修改
因为elasticsearch需要在非root的用户下面操作,并且elasticsearch的文件夹的权限也为非root权限, 因此我们需要创建一个用户进行操作,我们创建一个elastic用户,并赋予该目录的权限。
命令如下:
adduser elastic
chown -R elastic:elastic /opt/elk/masternode
这里我们顺便再来指定ElasticSearch数据和日志存放的路径地址,我们可以先使用df -h命令查看当前系统的盘主要的磁盘在哪,然后在确认数据和日志存放的路径,如果在/home 目录下的话,我们就在home目录下创建ElasticSearch数据和日志的文件夹,这里为了区分吗,我们可以根据不同的节点创建不同的文件夹。这里的文件夹创建用我们刚刚创建好的用户去创建,切换到elastic用户,然后创建文件夹。
su elastic
mkdir /home/elk
mkdir /home/elk/masternode
mkdir /home/elk/masternode/data
mkdir /home/elk/masternode/logs
mkdir /home/elk/datanode1
mkdir /home/elk/datanode1/data
mkdir /home/elk/datanode1/logs
主节点(master)配置
创建成功之后,我们先修改masternode节点的配置,修改完成之后在同级目录进行copy一下,名称为datanode1,然后只需少许更改datanode节点的配置即可。这里我们要修改elasticsearch.yml和jvm.options文件即可! 注意这里还是elastic用户!
cd /opt/elk/
vim masternode/config/elasticsearch.yml
vim masternode/config/jvm.options
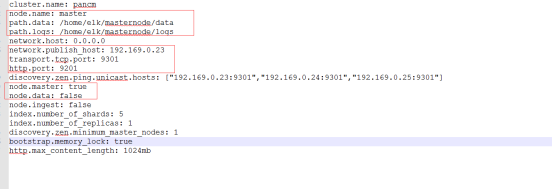
masternode的elasticsearch.yml文件配置如下:
cluster.name: pancm
node.name: master
path.data: /home/elk/masternode/data
path.logs: /home/elk/masternode/logs
network.host: 0.0.0.0
network.publish_host: 192.169.0.23
transport.tcp.port: 9301
http.port: 9201
discovery.zen.ping.unicast.hosts: ["192.169.0.23:9301","192.169.0.24:9301","192.169.0.25:9301"]
node.master: true
node.data: false
node.ingest: false
index.number_of_shards: 5
index.number_of_replicas: 1
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: true
http.max_content_length: 1024mb
elasticsearch.yml文件参数配置说明:
cluster.name: 集群名称,同一集群的节点配置应该一致。es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
node.name: 该节点的名称。 path.data: 数据存放的路径。 path.logs: 日志存放的路径。
- network.host: 设置ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。
- network.publish_host: 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。
- transport.tcp.port:设置节点间交互的tcp端口,默认是9300。
- http.port:设置对外服务的http端口,默认为9200。
- discovery.zen.ping.unicast.hosts: 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
- node.master: 指定该节点是否有资格被选举成为node,默认是true。 node.data: 指定该节点是否存储索引数据,默认为true。
- node.ingest: 指定该节点是否使用管道,默认为true。
- index.number_of_shards:设置默认索引分片个数,默认为5片。
- index.number_of_replicas:设置默认索引副本个数,默认为1个副本。
- discovery.zen.minimum_master_nodes: 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)。
- bootstrap.memory_lock: 设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,Linux下可以通过
ulimit -l unlimited命令。 http.max_content_length: 设置内容的最大容量,默认100mb。
-…
这里在顺便说下ElasticSearch节点的属性。
- node.master: true 并且 node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据。
如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。ElasticSearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,因为这样相当于主节点和数据节点的角色混合到一块了。
- node.master: false 并且 node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。 这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据,后期提供存储和查询服务。 - node.master: true 并且 node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点,这个节点我们称为master节点。 - node.master: false node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
- node.ingest: true
执行预处理管道,不负责数据和集群相关的事物。
它在索引之前预处理文档,拦截文档的bulk和index请求,然后加以转换。
将文档传回给bulk和index API,用户可以定义一个管道,指定一系列的预处理器。
elasticsearch.yml文件配置示例图
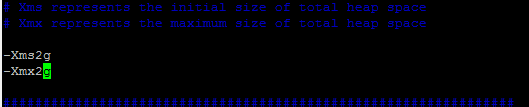
将jvm.options配置Xms和Xmx改成2G,配置如下:
-Xms2g
-Xmx2g
关于ElasticSearch更多配置可以参考ElasticSearch官方文档!
数据节点节点(data)配置
在配置完masternode节点的ElasticSearch之后,我们再来配置datanode节点的,我们将masternode节点copy一份并重命名为datanode1,然后根据上述示例图中红色框出来简单更改一下即可。
命令如下:
cd /opt/elk/
cp -r masternode/ datanode1
vim datanode1/config/elasticsearch.yml
vim datanode1/config/jvm.options
datanode的elasticsearch.yml文件配置如下:
cluster.name: pancm
node.name: data1
path.data: /home/elk/datanode/data
path.logs: /home/elk/datanode/logs
network.host: 0.0.0.0
network.publish_host: 192.169.0.23
transport.tcp.port: 9300
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.169.0.23:9301","192.169.0.24:9301","192.169.0.25:9301"]
node.master: false
node.data: true
node.ingest: false
index.number_of_shards: 5
index.number_of_replicas: 1
discovery.zen.minimum_master_nodes: 1
bootstrap.memory_lock: true
http.max_content_length: 1024mb
将jvm.options配置Xms和Xmx改成8G,配置如下:
-Xms8g
-Xmx8g
注:配置完成之后需要使用ll命令检查一下masternode和datanode1权限是否属于elastic用户的,若不属于,可以使用chown -R elastic:elastic +路径 命令进行赋予权限。
上述配置完成之后,可以使用相同的方法在其他的机器在操作一次,或者使用ftp工具进行传输,又或者使用scp命令进行远程传输文件然后根据不同的机器进行不同的修改。
scp命令示例:
jdk环境传输:
scp -r /opt/java root@slave1:/opt
scp -r /opt/java root@slave2:/opt
ElasticSearch环境传输:
scp -r /opt/elk root@slave1:/opt
scp -r /home/elk root@slave1:/opt
scp -r /opt/elk root@slave2:/opt
scp -r /home/elk root@slave2:/opt
3,启动ElasticSearch
这里还是需要使用elastic用户来进行启动,每台机器的每个节点都需要进行操作!
在/opt/elk的目录下输入:
su elastic
cd /opt/elk
./masternode/bin/elasticsearch -d
./datanode1/bin/elasticsearch -d
启动成功之后,可以输入jps命令进行查看或者在浏览器上输入 ip+9200或ip+9201进行查看。
出现以下界面表示成功!


四、Kibana 安装
kinaba安装只需要在一台机器上部署即可,直接通过root用户进行操作,需要注意的是kinaba需要和ElasticSearch服务器网络ping通即可。
1,文件准备
将下载下来的kibana-6.5.4-linux-x86_64.tar.gz的配置文件进行解压
在linux上输入:
tar -xvf kibana-6.5.4-linux-x86_64.tar.gz
然后移动到/opt/elk 里面,然后将文件夹重命名为 kibana6.5.4
输入:
mv kibana-6.5.4-linux-x86_64 /opt/elk
mv kibana-6.5.4-linux-x86_64 kibana6.5.4
2,配置修改
进入文件夹并修改kibana.yml配置文件:
cd /opt/elk/kibana6.5.4
vim config/kibana.yml
将配置文件中的:
server.host: "localhost"
修改为:
server.host: "192.169.0.23"
然后一行新增,这行的意思是不使用帐号密码登录
xpack.security.enabled: false
保存退出!

3,Kinaba 启动
使用root用户进行启动。
在kibana6.5.4文件夹目录输入:
nohup ./bin/kibana >/dev/null 2>&1 &
浏览器输入:

五、错误问题解决办法
1,max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
原因: 内存限制太小了!
解决办法: 修改最大内存限制,参考Linux环境配置的第一条!
2,max number of threads [2048] for user [elastic] is too low, increase to at least [4096]
原因: 线程数限制太少了!
解决办法: 修改最大线程数限制,参考Linux环境配置的第二条!
3, max file descriptors [65535] for elasticsearch process likely too low, increase to at least [65536]
原因: 打开文件个数太少了!
解决办法: 修改最打开文件个数,参考Linux环境配置的第三条!
4,ERROR:bootstrap checks failed
原因:未锁定内存。
解决办法:在报错机器上的elasticsearch.yml配置文件中添加bootstrap.memory_lock: true配置!
其它
ElasticSearch和head插件 Windows版的安装:
https://www.cnblogs.com/xuwujing/p/8998168.html
音乐推荐
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:http://www.panchengming.com